
The Technological and Regulatory AI Divide: Determining Who Benefits from an AI Summer

Photo by Pete Linforth on Pixabay
By Vivian Reutens
Government attention paid to artificial intelligence has fluctuated since its formal conception in 1956, when the term was coined at the Dartmouth Summer Research Project on Artificial Intelligence. High hopes and Cold War-motivated US government funding in the 1970s gave way to an “AI winter” when the nascent technology fell short of expectations for machine translation. Further advancements in the 1980s and 1990s spurred a boom in private and defense-motivated government investment alike which eventually declined due to challenges in implementation.
Decades later, the world has seen the meteoric rise of generative AI systems, most famously ChatGPT. Despite this, in 2016, the US was the only country that had published official documents containing explicit AI governance principles. It wasn’t until Google’s introduction of the revolutionary Transformer Model in 2017 that global government and corporate investment truly began to take off once more — a new “AI summer.” A surge in regulation soon followed.
Today, AI is projected to contribute a 1.5% boost to annual US productivity growth over the next ten years, a significant figure considering productivity growth has averaged 1.4% over the past fifteen years. It’s no surprise that countries are scrambling to come out on top in this century’s newest tech race.
Concerning, then, is the AI divide emerging between high-income countries and low- and middle-income countries (LMICs). High-income countries are better positioned to disproportionately leverage AI’s productivity boosts given their workforce distributions and existing digital infrastructure. These advantages enable them to set standards for the rest of the world. The concentration of influence in a few high-income countries risks neglecting the specific needs of developing countries in AI policy development. If LMICs are unable to develop their AI infrastructure and encourage local innovation, they face the risk of being excluded from high value-segments of the AI stack, becoming mere consumers of advanced AI at best. This will deepen the AI divide, undermining the ability of LMICs to assert regulatory sovereignty over AI.
AI Infrastructure and Technology
High-income countries control multiple stages of the AI value chain, which consists of infrastructure, model training and testing, and deployment in user-facing applications. As a result, they also reap the majority of the profits. For example, the market for foundation models like GPT4, which are trained on massive datasets to complete a variety of tasks and act as a base for downstream applications, is dominated by American firms, including Google, OpenAI, Meta, Microsoft, and DeepMind.
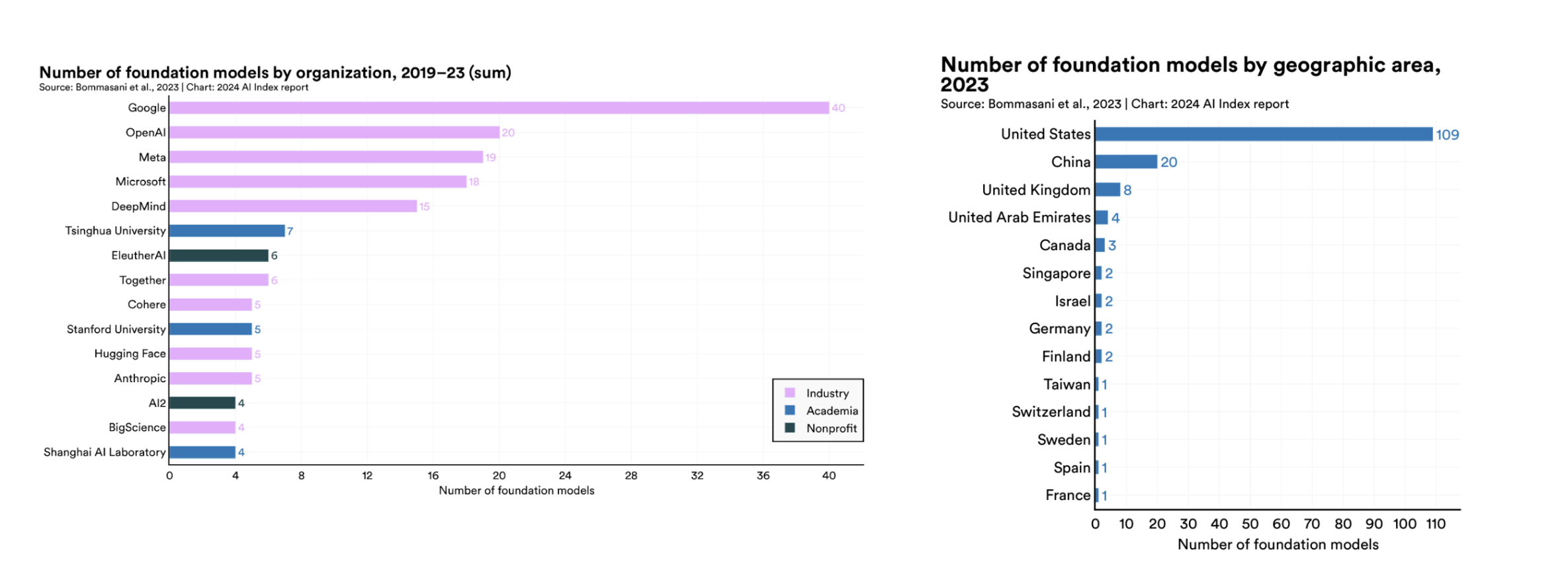
Figure I: Foundation Models by Organization and by Geographic Area. Stanford HAI (2024)
Concentration of AI infrastructure – which includes datasets, data networks, hardware, software, and machine learning models necessary for AI development, testing, and implementation – is key to high-income countries’ prominence across the AI stack. For instance, the data storage facilities required to train foundation models are mostly located in high-income countries. The US, UK, and Germany alone constitute 49% of the world’s data centers and cloud service providers. These facilities have high baseline capital requirements in energy usage and construction, and require intensive regulatory coordination with municipal authorities. These challenges, coupled with the skilled labor needed to carry out these projects, create significant barriers for emerging economies looking to enter the market.
As a result, developing economies risk losing out on a key multiplier effect: initial investments in data centers and their accompanying infrastructure often invite further investment in the local digital economy. The lack of data centers in low-income and lower-middle-income countries, which house only around 4% of the world’s total, means that most data processing is happening elsewhere, limiting the ability of these countries to control or regulate how data collected from their users is being processed, stored or contracted. In turn, their ability to influence the AI models trained on that data and sold back to their citizens is also impaired.
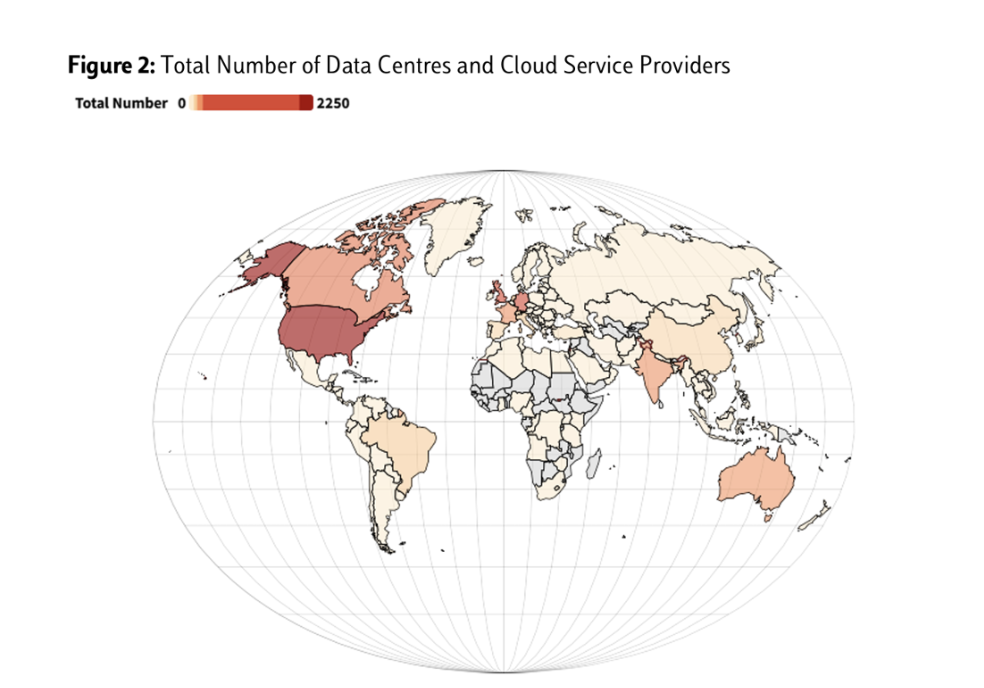
Figure II: Total Number of Data Centers and Cloud Service Providers. The Uneven Geography of Digital Infrastructure: Does It Matter? (2024)
Compute resources, the bespoke hardware like graphics processing units (GPUs) and AI-tailored semiconductor chips needed for models to perform tasks and calculations, are another aspect of AI infrastructure concentrated in high-income countries. The US dominates the global semiconductor supply chain, contributing 39% of its total value as of 2021. South Korea, the European Union, Japan, China, and Taiwan contribute another 59%. Specialized designs produced in these countries add significant value to the end product but require sophisticated production equipment and workers with advanced degrees. This surmounts to heavy fixed costs that pose high barriers to entry in both chip development and manufacturing. Developing economies are left consuming but not building advanced technologies, increasing reliance on high-income nations for access.
The uneven global distribution of compute infrastructure also means that countries lacking such infrastructure, which are mostly lower middle-income and lower-income countries, will have little opportunity to influence AI via territorial jurisdiction. States that have compute infrastructure within their borders have greater ability to enforce regulations against it. For example, they can intervene at more points throughout the process by which data enters and exits data centers. On the other hand, even if states without physical compute create AI or data regulation with extraterritorial intent, they may lack the political capital or jurisdictional authority needed to enforce policies abroad. This undermines the digital sovereignty of states without physical compute infrastructure, and leaves them with little leverage to shape the future of AI.
To combat this, many countries are starting to pass data localization measures, which require data generated by a country’s citizens to be stored and/or processed within the country. Reasons cited for such measures include easier enforcement of data protection laws, economic stimulation of nascent AI sectors, and improving access to domestically-created data stored abroad. These measures have sparked debates over whether limiting trans-border data flows is beneficial to developing countries’ economies, and whether it allows states to surveil and/or censor their own citizens more easily. While the jury is still out on this issue, these debates highlight the need for robust, localized regulatory frameworks that both address the general technical and security risks associated with AI and also ensure that the regulatory sovereignty of all nations – especially those lacking compute resources – is respected and upheld.
AI Regulation
As AI models, infrastructure, and technology advance in scale and scope, so does the conversation on AI regulation. Protecting data privacy, reinforcing intellectual property rights, and ensuring that AI systems align with human values and ethics are essential for the safe and ethical use of AI. Beyond these concerns, regulation also plays a critical role in the AI race. The region that sets the most stringent standards forces companies that wish to operate in that region to follow its regulations. Companies that hope to operate in multiple regions must comply with the strictest set of regional standards, meaning that the region that sets forth the most comprehensive set of regulations will influence how AI systems are created, deployed, and used across the world.
So far, the EU, the US, and China are the dominant players in this field, having created almost two-thirds of the over 470 AI policies introduced between 2011 and 2023. These superpowers are aiming to be first-movers in AI regulation and development. While China made the first move in 2017 with the Next Generation AI Development Plan, the EU took the lead in 2023 when it reached a provisional agreement on the AI Act, which comprises the most comprehensive set of regulations in the field. The White House issued the less extensive AI Executive Order the same year, signalling the US’s intent to also have a stake in the future of AI development.
Influence in international governing bodies is similarly concentrated. While all Western European countries and the US are active in seven non-UN international AI governance initiatives, 118 countries, most of which are located in Africa, Asia, Oceania, and Latin America, are not. Furthermore, of the 39 members sitting on the UN’s High-level Advisory Board on AI, less than ten are associated with LMICs in the Global South.

Figure III: Representation in seven non-United Nations international AI governance initiatives. UN AI Advisory Body (2024)
The dominance of a handful of wealthy parties in the AI regulatory space leaves little room for diverse priorities, cultural values, and socioeconomic conditions. In the long run, this is likely to stunt developing countries’ ability to nurture nascent AI industries. Leading economies’ concerns mainly revolve around systemic failure and risks like privacy violation, mis/disinformation, divergence from human values, and more. However, for many LMICs, developing the capacity to fully realize AI’s potential benefits is a higher priority than curbing its misuse. If the “Brussels Effect” – which describes how the EU’s regulatory policies often influence global standards – affects the standards emerging economies develop, as the GDPR influenced global data policy, strict European compliance requirements may be extended to emerging economies whose developers may struggle to meet them. Global policy regimes that prioritize control and containment of AI will make it even harder for developing countries to develop local AI capacity.
As AI systems become ingrained in day-to-day life, exclusion from global regulatory decision making threatens devastating consequences for cultural and historical representation. As companies seek to make AI available to more markets, they will require increasingly localized data in order to better serve those communities. With this comes already materializing concerns that models developed in high income countries will misrepresent or distort indigenous knowledge from developing countries and/or marginalized groups. When OpenAI debuted Whisper, an open source automatic speech recognition (ASR) tool, the model often failed to accurately process te reo Māori (the native Māori language), reporting a 73% error rate. Indigenous to New Zealand, the Māori people have been marginalized by colonization and systemic inequities in the country. As of 2018, less than 15% of Māori can speak, read, or write te reo Māori. When the Māori media organization Te Hiku Media investigated the origins of the data used to train Whisper, OpenAI was unresponsive.
Whisper’s release sparked concern that te reo Māori would be bastardized by faulty ASR, and that outsiders seeking to capitalize on the te reo Māori economy would benefit instead of indigenous Māori speakers. Development that excludes informed input from developing countries and marginalized communities results in deployment that risks perpetuating and deepening global and societal inequities. Global policy that does not protect against this disproportionately disadvantages communities in countries that rely on other countries to supply AI technology.
Final Reflections
Closing the technological and regulatory AI divide is crucial to ensure that global AI regulatory regimes take the diverse needs of LMICs into account. To this end, developing a vision for AI implementation and regulation should be a priority item on LMICs’ to-do lists. While only 12 out of the 95 countries that have or are developing a national AI strategy as of 2023 are low- or lower-middle-income, there are still encouraging signs of momentum in this space. Notably, half of the AI strategies published or announced last year came from low- or lower-middle-income countries.

Figure IV: AI strategies published per year (2017-2023). Oxford Insights (2023)
Countries with a national strategy on AI. Stanford HAI(2024)
A key item for countries developing AI strategies should be investment in infrastructure as well as human capital. Digital and electrical infrastructure are crucial for running and testing AI models, penetrating the AI value chain, and gaining sovereignty over how the data fed to AI models is managed. Teaching local communities how to use AI is also necessary to maintain these systems and foster local AI development.
Alongside these opportunities, policymakers should also consider both general risks associated with AI use as well as gaps in AI safety and representation specific to their local historical and cultural contexts. However, regulation should be tailored to their specific socioeconomic needs so as not to unnecessarily stifle local AI development. In doing so, these countries can both safeguard against risks associated with AI and leverage its potential to drive economic growth.
Vivian Reutens is a freshman from the SF Bay Area studying economics and mathematics at New York University. She is interested in public policy and the ways national initiatives are shaped by supranational policies and corporate interests. On the weekends, she enjoys walking to different neighborhoods and scoping out new bakeries.